Firefox 54がとてつもなく速い!! [ソフトウェア]
本日、Firefox ウェブ ブラウザーを最新の " Firefox 54 " へとアップデート致しましたところ、そのあまりの高速っぷりに驚いてしまいました!
Firefoxの動作は今までも充分速く感じていたのですが、今度のFirefox 54は桁違いの軽快さです。
マルチプロセス動作が標準で有効化され、ヴィデオカードなどGPUによるハードウェア アクセラレーションも対応が進み、メモリーの使用量は少ないままに、ページの表示は一瞬で終わりますし、HTML5のCanvas要素を用いた自作のウェブ アプリケーションも動作が更に滑らかになりました!
こんなに速くなるとは予想しておりませんでしたが、棚からぼた餅です。
Firefox 最高!
(共謀罪最低!)
Firefoxの動作は今までも充分速く感じていたのですが、今度のFirefox 54は桁違いの軽快さです。
マルチプロセス動作が標準で有効化され、ヴィデオカードなどGPUによるハードウェア アクセラレーションも対応が進み、メモリーの使用量は少ないままに、ページの表示は一瞬で終わりますし、HTML5のCanvas要素を用いた自作のウェブ アプリケーションも動作が更に滑らかになりました!
こんなに速くなるとは予想しておりませんでしたが、棚からぼた餅です。
Firefox 最高!
(共謀罪最低!)
Firefox 50にアップデートしたらYouTubeなどの動画が再生出来なくなった場合の解決方法(Ubuntu環境)。 [ソフトウェア]
2016年11月16日に、オープン ソースのウェブ ブラウザーである " Firefox " の最新ヴァージョンの " Firefox 50 " がリリースされました。
このヴァージョンでは大規模な改良が加えられております。
"GIGAZINE" の記事 "「Firefox 50」正式版がリリース、キーボードショートカットの更新やページ内検索機能を強化" のURL:
http://gigazine.net/news/20161116-firefox-50/
[関連情報]
"TechCrunch Japan" の記事 "多重処理を導入したFirefoxは応答性が400〜700%向上、バージョン52/53にかけて順次展開" のURL:
http://jp.techcrunch.com/2016/09/03/20160902multi-process-firefox-brings-400-700-improvement-in-responsiveness/
ところが、この " Firefox 50 " へのアップデートにより、私のUbuntu 16.04 LTSのOS環境では、YouTubeなどのHTML5動画の映像が正常に再生出来ず、最初の数フレームがずっと繰り返してしまうという不具合が発生致しました。
NVIDIA GeForce GTX750の為のグラフィクス ドライヴァーが問題かと思い、違うヴァージョンのドライヴァーをインストールしても直らず、 " Firefox 49 " にヴァージョンを戻してみましたところ、正常に動画が再生出来ました。
従って、明らかに " Firefox 50 " へのアップデートが原因でしたので、調べましたところ、 " Arch Linux " のウェブサイトのフォーラムに同じ問題が報告されておりました。
"Arch Linux Forums" / "Applications & Desktop Environments" の当該ページのURL:
https://bbs.archlinux.org/viewtopic.php?id=219626
当該スレッドの2ページ目に投稿されていた情報をもとに、Firefoxでアドレス バーに " about:support " と入力してエンター キーを押したところ、 " アプリケーション基本情報 " の " マルチプロセスウィンドウ " の設定値が " 0/1 (アドオンにより無効) " となっておりました。
オンライン フォーラムによるとこれが有効化されていないといけないそうでしたので、アドオンを無効化して再起動する事に致しました。
私の場合は何のアドオンが原因だったかと申しますと、Ubuntu 14.04 LTSを初めてインストールした際に自動的にインストールされた、 " Ubuntu Modifications " が原因でした。
このアドオンを無効化して再起動致しましたところ、 " マルチプロセスウィンドウ " の設定値が " 1/1 (既定で有効) " に変わっておりました。
そして、YouTubeなどのHTML5動画は元通り、正常に再生出来るようになりました。
尚、 " Ubuntu Modifications " を無効化してからも私は特にこれと言った問題には遭遇しておりません。
このヴァージョンでは大規模な改良が加えられております。
"GIGAZINE" の記事 "「Firefox 50」正式版がリリース、キーボードショートカットの更新やページ内検索機能を強化" のURL:
http://gigazine.net/news/20161116-firefox-50/
[関連情報]
"TechCrunch Japan" の記事 "多重処理を導入したFirefoxは応答性が400〜700%向上、バージョン52/53にかけて順次展開" のURL:
http://jp.techcrunch.com/2016/09/03/20160902multi-process-firefox-brings-400-700-improvement-in-responsiveness/
ところが、この " Firefox 50 " へのアップデートにより、私のUbuntu 16.04 LTSのOS環境では、YouTubeなどのHTML5動画の映像が正常に再生出来ず、最初の数フレームがずっと繰り返してしまうという不具合が発生致しました。
NVIDIA GeForce GTX750の為のグラフィクス ドライヴァーが問題かと思い、違うヴァージョンのドライヴァーをインストールしても直らず、 " Firefox 49 " にヴァージョンを戻してみましたところ、正常に動画が再生出来ました。
従って、明らかに " Firefox 50 " へのアップデートが原因でしたので、調べましたところ、 " Arch Linux " のウェブサイトのフォーラムに同じ問題が報告されておりました。
"Arch Linux Forums" / "Applications & Desktop Environments" の当該ページのURL:
https://bbs.archlinux.org/viewtopic.php?id=219626
当該スレッドの2ページ目に投稿されていた情報をもとに、Firefoxでアドレス バーに " about:support " と入力してエンター キーを押したところ、 " アプリケーション基本情報 " の " マルチプロセスウィンドウ " の設定値が " 0/1 (アドオンにより無効) " となっておりました。
オンライン フォーラムによるとこれが有効化されていないといけないそうでしたので、アドオンを無効化して再起動する事に致しました。
私の場合は何のアドオンが原因だったかと申しますと、Ubuntu 14.04 LTSを初めてインストールした際に自動的にインストールされた、 " Ubuntu Modifications " が原因でした。
このアドオンを無効化して再起動致しましたところ、 " マルチプロセスウィンドウ " の設定値が " 1/1 (既定で有効) " に変わっておりました。
そして、YouTubeなどのHTML5動画は元通り、正常に再生出来るようになりました。
尚、 " Ubuntu Modifications " を無効化してからも私は特にこれと言った問題には遭遇しておりません。
動画を高画質化して再投稿致しました。 [ソフトウェア]
先日2016年9月11日日曜日に私が観に行った、群馬県邑楽郡大泉町の " 文化むら " の " 大ホール " で開催された、 " 第8回 文化むら キッズ ダンス フェスタ " (Kids Dance Festa)での出演チーム " moda " のダンス パフォーマンスを私が撮影した動画を、インターネット動画投稿サイトの " Dailymotion " に投稿してブログ内に掲載したのですが、今日、動画の画質と音質を向上させて再投稿致しました。
関係者からの許諾は得ておりませんが、どうか御容赦下さい。
Bunkamura Kids Dance Festa (2016_09_11)_2 投稿者 Hard_Solid_Bass
私が撮影した " moda " のダンス パフォーマンスの動画です。
プレイヤーの画質を1080pに設定して全画面表示するとある程度良好な画質で再生出来ます。
DailymotionはCDN (Contents Delivery Network)として " Limelight Orchestrate " というサーヴィスを利用している事が2016年2月17日に発表されておりますが、その割には帯域幅が狭く、低画質でしか再生できない事が多いようです。
特に夜間はアクセス過多でサーヴァーが過負荷になり、再生が止まる事もしばしばあるようです。
ブログ記事: 大泉町 "文化むら キッズ ダンス フェスタ" を今年も観に行って来ました。
http://crater.blog.so-net.ne.jp/2016-09-14
私はこのヴィデオをSONYのコンパクト ディジタル カメラ DSC-RX100で撮影致しました。
このカメラは2012年6月22日発売の古いモデルであり、且つ小型ですので、動画の暗所撮影性能は余り高くありません。
ダンス パフォーマンスを撮影した文化むら大ホールは照明の演出が素晴らしく凝っており、様々な色のスポットライトが激しく明滅し、背景もスクリーンになっていて様々な色に照らし出されます。流石にレーザー ビームはありませんが。
そして私が撮影した場所は2階のバルコニーからで、このカメラの最大ズーム倍率である3.6倍より少し手前位の倍率でしたのでF値が大きくなり、画像が暗くなります。
撮影した動画は非常にノイズが多く、被写体の速い動きは像がブレておりました。
照明が明滅するタイミングでは盛大なディジタル圧縮ノイズが出ており、暗い場面ではザラついたノイズが乗り、被写体の輪郭にはモスキート ノイズが出ておりました。
私はこの動画の画質の改善を試みました。
色々試した中で上手く行った方法は、実に簡単なものでした。
処理は " 端末 " によるコマンド ラインを使用致します。
まずは動画ファイルを " ffmpeg " で連続の静止画像群と音声ファイルに分離します。
ファイル パスやファイル名、コーデックなどは適宜変更致します。
" XnConvert " という大量の画像を一括で処理出来る、無料のソフトウェアで以下の処理を行います。
" 動作 " タブを開き、 " 動作を追加 " ボタンを押し、 " フィルタ " の " ノイズ除去 " を選択致します。
このノイズ除去フィルターは非常に優れており、被写体の輪郭の周辺にある、モスキート ノイズなどのノイズを選択的に、効果的に除去出来ます。
このノイズ除去フィルターは複数回適用しても全体の画質はほとんど損なわれません。
ノイズ除去した上でそのままXnConvertで " フィルタ " の " ピント強調 " を適用致します。
すると画像が鮮鋭化されます。
"XnConvert" の公式ウェブサイトのURL:
http://www.xnview.com/en/xnconvert/
次に分離しておいた音声ファイルをオープンソースで無料の音声波形編集ソフトウェアである " Audacity " で編集致しました。手順は以下の様に致しました。
Audacityにaudio.ac3 ファイルを取り込む。(1)
(1)のステレオ トラックを複製する。(2)
(2)のトラックに対してLow-Pass Filter( 200[Hz], -12[dB/Octave] )を適用する。
(1)と(2)を合成。(3)
(3)のトラックに対してHPF( 30[Hz], -36[dB/Octave] )を適用する。
(3)のトラックに対してコンプレッサー( 閾値-6[dB], ノイズ フロア-60[dB], レシオ6:1, アタック タイム0.10[秒], リリース タイム1[秒], ゲイン調整無し, ピークに基く圧縮有り )を適用する。
(3)のトラックに対して増幅( 最大値-0.01[dB] )を適用する。
(3)のトラックに対して導入部分にフェードインを適用する。
最後にこれを320[kbps]の.ac3形式のファイルとして書き出す。
"Audacity" の公式ウェブサイトのURL:
http://web.audacityteam.org/
そしてffmpegにて連番の静止画像群と音声ファイルを結合して再エンコードして完成です。
ところで、XnConvertのノイズ除去フィルターでは輪郭の周辺のモスキート ノイズなどのノイズ以外のノイズは除去しませんので、他の種類のノイズを除去したい場合には別のソフトウェアで処理する必要がございます。
例えば、ディジタル圧縮のブロック状ノイズならば " waifu2x " のNoise Reductionが効きます。
ブログ記事: 最高峰の学習型画像拡大ソフトウェアを使ってみました。
http://crater.blog.so-net.ne.jp/2015-11-26
他には、動画ファイルのまま、 " ffmpeg " のウェーヴレット変換によるノイズ低減処理もございます。
以下にffmpegでアンシャープ マスクによる鮮鋭化とウェーヴレット変換によるノイズ低減処理を行うコマンドを例示致します。
" vaguedenoiser " がウェーヴレット変換によるノイズ低減フィルターです。
" threshold " の値が大きい程沢山のノイズを除去しますが、同時に細部がぼやけてしまいます。
" percent " の値がノイズ低減処理を反映させる割合で、値が小さい程効果が弱くなります。
詳しくはffmpegの公式ドキュメントを御覧下さい。
"ffmpeg" の公式ドキュメントの "vaguedenoiser" フィルターに関する項目のURL:
https://ffmpeg.org/ffmpeg-filters.html#vaguedenoiser
ついでにffmpegによる強力な手振れ補正処理を行う方法も記載致します。
2016年9月21日現在に於いてはUbuntu 16.04 LTSでffmpegで高性能な手振れ補正を行うには " vid.stab " を使用する必要がございますが、その為にはffmpegを自身でビルドする必要がございます。
注意事項と致しまして、使用したい機能がある場合は自身でそれを追加し、有効化する必要がございます。
まず、 " vid.stab " をインストール致します。
次に、 " libx264 " をインストール致します。
続いて、 " libx265 " もインストール致します。
" ffmpeg " に必要なライブラリーを纏めてインストール致します。
ライブラリーだけ残して " ffmpeg " のみを削除致します。
" ffmpeg " のコンパイルに必要な " YASM " をインストール致します。
" ffmpeg " のコンパイルとインストールを行います。
実行ファイル " ffmpeg " を " /usr/bin/ffmpeg " へ複製致します。
" libvidstab.so.1.1 " を " /usr/lib/x86_64-linux-gnu " へ複製致します。
必要なパスが通っている事を確認し、通っていない場合は適宜、環境変数にパスを設定しておきます。
手振れ補正の為に動画の手振れの量を解析致します。
解析結果が " transforms.trf " というファイルに記録されます。
" shakiness " は値が大きい程激しくて速い揺れに対応します。
" mincontrast " は揺れ検出で使用する最小のコントラスト値です。画像の中でこの値より大きなコントラストを持った領域を使用して揺れの検出を行います。この値より小さなコントラストの領域は無視されます。
手振れ補正とクロッピングを実行してエンコードするコマンドの例です。
" smoothing " は値が大きい程、長周期の揺れを補正します。
具体的には、 (数値 ^ 2 + 1) 枚のフレームを揺れの波形をローパス フィルタリングする際に使用します。
この例では、 " crop " で画像の高さを1080[pixel]から720[pixel]に切り取って、 " pad " で上下に黒帯を付けております。
これにより大抵の手振れは補正可能な筈です。
また、ffmpegで書き出した連続番号画像ファイル群に対して、 " ImageMagick " という無料の画像処理ソフトウェアを使用する事も出来ます。
選択的ノイズ除去の後、鮮鋭化の処理を行うコマンドの例を示します。
引数の " -selective-blur " の構文は " radiusxsigma{+threshold} " です。
" threshold " で設定した閾値以下のコントラストを持つ領域だけを暈します。
処理した後は前述の方法で連番画像から映像に戻して音声ファイルと結合させます。
"ImageMagick" の公式ウェブサイトのコマンドライン オプションのドキュメントの "selective-blur" の項目のURL:
http://www.imagemagick.org/script/command-line-options.php#selective-blur
更にこちらは " Fiji " という画像処理ソフトウェアを使用したノイズ除去の方法です。
" Fiji " は " ImageJ " の便利なプラグイン全部入りのパッケージです。
" ImageJ " は医学、生理学、生物学などの分野の研究者達が使用する事が多いオープンソースで無料でJava VM上で動作する画像処理ソフトウェアです。
Java仮想マシンが動作する環境にしてある事が前提です。
まずは公式ウェブサイトより " Fiji " をダウンロードします。
"Fiji" の公式ウェブサイトのURL:
http://fiji.sc/
" Fiji " を起動してアップデートを済ませて再起動させます。
" Plugins " メニューから " Macros " - " Startup Macros... " を選択します。
ポップアップした " StartupMacros.fiji.ijm " ウィンドウで " File " メニューから " New " を選択します。
以下のマクロをコピー&ペーストします。
ファイル パスは適宜変更致します。
" Language " メニューから " IJ 1 Macro " を選択します。
" Run " ボタンを押すと、指定したディレクトリーにある連番画像の全部を1枚づつ読み込んでは " Anisotropic Diffusion " (異方性拡散)処理が実行されます。
この処理は優秀で、被写体の輪郭や必要な細部の絵柄を比較的元通りに残したまま、ザラついたノイズだけを暈す事が出来ます。
処理が終わると直ぐに画像はPNG ファイル形式で保存され、開かれていた画像ファイルは閉じられて、次の画像が読み込まれます。
UbuntuなどのLinux ディストリビューションのOS環境ではこれらの様にオープンソースであったり、無料であったりする(勿論、金銭の寄付が可能であればするべきです)ソフトウェアにより動画の画質改善処理が行えます。
以上、文字ばかりで申し訳ございませんでしたが、私の覚え書き的な記事でした。
関係者からの許諾は得ておりませんが、どうか御容赦下さい。
Bunkamura Kids Dance Festa (2016_09_11)_2 投稿者 Hard_Solid_Bass
私が撮影した " moda " のダンス パフォーマンスの動画です。
プレイヤーの画質を1080pに設定して全画面表示するとある程度良好な画質で再生出来ます。
DailymotionはCDN (Contents Delivery Network)として " Limelight Orchestrate " というサーヴィスを利用している事が2016年2月17日に発表されておりますが、その割には帯域幅が狭く、低画質でしか再生できない事が多いようです。
特に夜間はアクセス過多でサーヴァーが過負荷になり、再生が止まる事もしばしばあるようです。
ブログ記事: 大泉町 "文化むら キッズ ダンス フェスタ" を今年も観に行って来ました。
http://crater.blog.so-net.ne.jp/2016-09-14
私はこのヴィデオをSONYのコンパクト ディジタル カメラ DSC-RX100で撮影致しました。
このカメラは2012年6月22日発売の古いモデルであり、且つ小型ですので、動画の暗所撮影性能は余り高くありません。
ダンス パフォーマンスを撮影した文化むら大ホールは照明の演出が素晴らしく凝っており、様々な色のスポットライトが激しく明滅し、背景もスクリーンになっていて様々な色に照らし出されます。流石にレーザー ビームはありませんが。
そして私が撮影した場所は2階のバルコニーからで、このカメラの最大ズーム倍率である3.6倍より少し手前位の倍率でしたのでF値が大きくなり、画像が暗くなります。
撮影した動画は非常にノイズが多く、被写体の速い動きは像がブレておりました。
照明が明滅するタイミングでは盛大なディジタル圧縮ノイズが出ており、暗い場面ではザラついたノイズが乗り、被写体の輪郭にはモスキート ノイズが出ておりました。
私はこの動画の画質の改善を試みました。
色々試した中で上手く行った方法は、実に簡単なものでした。
処理は " 端末 " によるコマンド ラインを使用致します。
まずは動画ファイルを " ffmpeg " で連続の静止画像群と音声ファイルに分離します。
|
ファイル パスやファイル名、コーデックなどは適宜変更致します。
" XnConvert " という大量の画像を一括で処理出来る、無料のソフトウェアで以下の処理を行います。
" 動作 " タブを開き、 " 動作を追加 " ボタンを押し、 " フィルタ " の " ノイズ除去 " を選択致します。
このノイズ除去フィルターは非常に優れており、被写体の輪郭の周辺にある、モスキート ノイズなどのノイズを選択的に、効果的に除去出来ます。
このノイズ除去フィルターは複数回適用しても全体の画質はほとんど損なわれません。
ノイズ除去した上でそのままXnConvertで " フィルタ " の " ピント強調 " を適用致します。
すると画像が鮮鋭化されます。
"XnConvert" の公式ウェブサイトのURL:
http://www.xnview.com/en/xnconvert/
次に分離しておいた音声ファイルをオープンソースで無料の音声波形編集ソフトウェアである " Audacity " で編集致しました。手順は以下の様に致しました。
Audacityにaudio.ac3 ファイルを取り込む。(1)
(1)のステレオ トラックを複製する。(2)
(2)のトラックに対してLow-Pass Filter( 200[Hz], -12[dB/Octave] )を適用する。
(1)と(2)を合成。(3)
(3)のトラックに対してHPF( 30[Hz], -36[dB/Octave] )を適用する。
(3)のトラックに対してコンプレッサー( 閾値-6[dB], ノイズ フロア-60[dB], レシオ6:1, アタック タイム0.10[秒], リリース タイム1[秒], ゲイン調整無し, ピークに基く圧縮有り )を適用する。
(3)のトラックに対して増幅( 最大値-0.01[dB] )を適用する。
(3)のトラックに対して導入部分にフェードインを適用する。
最後にこれを320[kbps]の.ac3形式のファイルとして書き出す。
"Audacity" の公式ウェブサイトのURL:
http://web.audacityteam.org/
そしてffmpegにて連番の静止画像群と音声ファイルを結合して再エンコードして完成です。
|
ところで、XnConvertのノイズ除去フィルターでは輪郭の周辺のモスキート ノイズなどのノイズ以外のノイズは除去しませんので、他の種類のノイズを除去したい場合には別のソフトウェアで処理する必要がございます。
例えば、ディジタル圧縮のブロック状ノイズならば " waifu2x " のNoise Reductionが効きます。
|
ブログ記事: 最高峰の学習型画像拡大ソフトウェアを使ってみました。
http://crater.blog.so-net.ne.jp/2015-11-26
他には、動画ファイルのまま、 " ffmpeg " のウェーヴレット変換によるノイズ低減処理もございます。
以下にffmpegでアンシャープ マスクによる鮮鋭化とウェーヴレット変換によるノイズ低減処理を行うコマンドを例示致します。
|
" vaguedenoiser " がウェーヴレット変換によるノイズ低減フィルターです。
" threshold " の値が大きい程沢山のノイズを除去しますが、同時に細部がぼやけてしまいます。
" percent " の値がノイズ低減処理を反映させる割合で、値が小さい程効果が弱くなります。
詳しくはffmpegの公式ドキュメントを御覧下さい。
"ffmpeg" の公式ドキュメントの "vaguedenoiser" フィルターに関する項目のURL:
https://ffmpeg.org/ffmpeg-filters.html#vaguedenoiser
ついでにffmpegによる強力な手振れ補正処理を行う方法も記載致します。
2016年9月21日現在に於いてはUbuntu 16.04 LTSでffmpegで高性能な手振れ補正を行うには " vid.stab " を使用する必要がございますが、その為にはffmpegを自身でビルドする必要がございます。
注意事項と致しまして、使用したい機能がある場合は自身でそれを追加し、有効化する必要がございます。
まず、 " vid.stab " をインストール致します。
|
次に、 " libx264 " をインストール致します。
|
続いて、 " libx265 " もインストール致します。
|
" ffmpeg " に必要なライブラリーを纏めてインストール致します。
|
ライブラリーだけ残して " ffmpeg " のみを削除致します。
|
" ffmpeg " のコンパイルに必要な " YASM " をインストール致します。
|
" ffmpeg " のコンパイルとインストールを行います。
|
実行ファイル " ffmpeg " を " /usr/bin/ffmpeg " へ複製致します。
|
" libvidstab.so.1.1 " を " /usr/lib/x86_64-linux-gnu " へ複製致します。
|
必要なパスが通っている事を確認し、通っていない場合は適宜、環境変数にパスを設定しておきます。
手振れ補正の為に動画の手振れの量を解析致します。
|
解析結果が " transforms.trf " というファイルに記録されます。
" shakiness " は値が大きい程激しくて速い揺れに対応します。
" mincontrast " は揺れ検出で使用する最小のコントラスト値です。画像の中でこの値より大きなコントラストを持った領域を使用して揺れの検出を行います。この値より小さなコントラストの領域は無視されます。
手振れ補正とクロッピングを実行してエンコードするコマンドの例です。
|
" smoothing " は値が大きい程、長周期の揺れを補正します。
具体的には、 (数値 ^ 2 + 1) 枚のフレームを揺れの波形をローパス フィルタリングする際に使用します。
この例では、 " crop " で画像の高さを1080[pixel]から720[pixel]に切り取って、 " pad " で上下に黒帯を付けております。
これにより大抵の手振れは補正可能な筈です。
また、ffmpegで書き出した連続番号画像ファイル群に対して、 " ImageMagick " という無料の画像処理ソフトウェアを使用する事も出来ます。
選択的ノイズ除去の後、鮮鋭化の処理を行うコマンドの例を示します。
|
引数の " -selective-blur " の構文は " radiusxsigma{+threshold} " です。
" threshold " で設定した閾値以下のコントラストを持つ領域だけを暈します。
処理した後は前述の方法で連番画像から映像に戻して音声ファイルと結合させます。
"ImageMagick" の公式ウェブサイトのコマンドライン オプションのドキュメントの "selective-blur" の項目のURL:
http://www.imagemagick.org/script/command-line-options.php#selective-blur
更にこちらは " Fiji " という画像処理ソフトウェアを使用したノイズ除去の方法です。
" Fiji " は " ImageJ " の便利なプラグイン全部入りのパッケージです。
" ImageJ " は医学、生理学、生物学などの分野の研究者達が使用する事が多いオープンソースで無料でJava VM上で動作する画像処理ソフトウェアです。
Java仮想マシンが動作する環境にしてある事が前提です。
まずは公式ウェブサイトより " Fiji " をダウンロードします。
"Fiji" の公式ウェブサイトのURL:
http://fiji.sc/
" Fiji " を起動してアップデートを済ませて再起動させます。
" Plugins " メニューから " Macros " - " Startup Macros... " を選択します。
ポップアップした " StartupMacros.fiji.ijm " ウィンドウで " File " メニューから " New " を選択します。
以下のマクロをコピー&ペーストします。
|
ファイル パスは適宜変更致します。
" Language " メニューから " IJ 1 Macro " を選択します。
" Run " ボタンを押すと、指定したディレクトリーにある連番画像の全部を1枚づつ読み込んでは " Anisotropic Diffusion " (異方性拡散)処理が実行されます。
この処理は優秀で、被写体の輪郭や必要な細部の絵柄を比較的元通りに残したまま、ザラついたノイズだけを暈す事が出来ます。
処理が終わると直ぐに画像はPNG ファイル形式で保存され、開かれていた画像ファイルは閉じられて、次の画像が読み込まれます。
UbuntuなどのLinux ディストリビューションのOS環境ではこれらの様にオープンソースであったり、無料であったりする(勿論、金銭の寄付が可能であればするべきです)ソフトウェアにより動画の画質改善処理が行えます。
以上、文字ばかりで申し訳ございませんでしたが、私の覚え書き的な記事でした。
無劣化で動画を分割出来る "Avidemux" 。 [ソフトウェア]
PCのOSが " Ubuntu 14.04 LTS " の環境で、動画記録形式として " AVCHD " 規格で動画圧縮規格が " MPEG4 AVC/H.264 " 、拡張子が " .MTS " の動画ファイルを無劣化で分割が出来るソフトウェアというと、ほぼ一択で " Avidemux " を使用する事になると思います。
" Avidemux " の " SourceForge " のページのURL:
http://avidemux.sourceforge.net/
私はSONYの " DSC-RX100 " というコンパクト ディジタル カメラを長い間使用しておりまして、1920 x 1080 (60p)の解像度で動画撮影したファイルをビット レートが28[Mbps]の上記規格のファイルとして記録しております。
そのファイルを不要場面のカットの為に一般的な動画編集ソフトウェアで分割してしまうと非可逆形式で再圧縮してしまう為、映像の品質が劣化してしまいます。
動画ファイルを無劣化でカットする為に、私が以前使用していたWindows 7の環境では " TSSniper " という無料のソフトウェアを使用しておりましたが、Ubuntu 14.04 LTSの環境ではこのソフトウェアはそのままでは動作しない為、 " Avidemux " という無料でオープンソースのソフトウェアを使わせて頂いております。
Avidemuxというソフトウェアは非常に優れたオープンソース ソフトウェアで、無劣化での分割の他、映像と音声の分離等も出来ますし、多くのファイル形式、圧縮形式に対応しております。
しかしながら、Ubuntuの公式リポジトリーで配布しているヴァージョンは動作に問題があり、ウィンドウに映像が正常に表示出来なかったりしました。
そこで、 " Launchpad " に登録されているPPA (Personal Package Archive)の1つである " Thanh Tung Nguyen " さんの " rebuntu16 " というPPAを自分の環境に追加し、Ubuntu 14.04 LTSでビルド済みの " Avidemux " をインストール致しました。
インストールしたのは " avidemux2.6-qt4 " です。
" Thanh Tung Nguyen " さんのPPAのURL:
https://launchpad.net/~rebuntu16
これで長らく快適に動画編集していたのですが、私の環境に於いて、最近のアップデートで動画ファイルを開く時にエラーが出て開けなくなってしまいました。更に新しいアップデートではアップデート中にエラーが出てアップデート不能になってしまいました。
そこで一旦このソフトウェアを " 端末 " から " sudo apt-get purge avidemux2.6-qt4 " として削除した後、 " sudo apt-get autoclean " 、 " sudo apt-get clean " 、 " sudo apt-get -f install " 、 " sudo apt-get autoremove " を実行しました。
私が何か不適切なパッケージ名を入力したりしたのかもしれませんが、再インストール時に依存関係の問題や競合が発生してしまいました。
その後、 " apt-get " の代わりにより高機能なパッケージ管理機能のフロントエンドである " aptitude " を " sudo apt-get install aptitude " としてインストールしてこれを用いてAvidemuxをインストール致しました。
" sudo aptitude install avidemux2.6-qt4 " を実行したところ、正常にインストールする事が出来ました。
インストールされたヴァージョンは " Avidemux 2.6.12 (Qt4) " です。
インストールされた " avidemux2.6-qt4 " を実行したところ、正常に動画ファイルを開く事が出来ました。
ところで、映像にフィルター処理等を施した場合等は再圧縮せざるを得ませんので、この様な場合には私はオープンソースで無料の優れた映像編集ソフトウェアである " OpenShot Video Editor " を使用しております。
"OpenShot Video Editor" の公式ウェブサイトのURL:
http://www.openshot.org/
初心者の方向けに、 " PPA " については次のページが参考になります。
"All About" の記事 "UbuntuのPPAて何?" のURL:
http://allabout.co.jp/gm/gc/438675/
" Avidemux " の " SourceForge " のページのURL:
http://avidemux.sourceforge.net/
私はSONYの " DSC-RX100 " というコンパクト ディジタル カメラを長い間使用しておりまして、1920 x 1080 (60p)の解像度で動画撮影したファイルをビット レートが28[Mbps]の上記規格のファイルとして記録しております。
そのファイルを不要場面のカットの為に一般的な動画編集ソフトウェアで分割してしまうと非可逆形式で再圧縮してしまう為、映像の品質が劣化してしまいます。
動画ファイルを無劣化でカットする為に、私が以前使用していたWindows 7の環境では " TSSniper " という無料のソフトウェアを使用しておりましたが、Ubuntu 14.04 LTSの環境ではこのソフトウェアはそのままでは動作しない為、 " Avidemux " という無料でオープンソースのソフトウェアを使わせて頂いております。
Avidemuxというソフトウェアは非常に優れたオープンソース ソフトウェアで、無劣化での分割の他、映像と音声の分離等も出来ますし、多くのファイル形式、圧縮形式に対応しております。
しかしながら、Ubuntuの公式リポジトリーで配布しているヴァージョンは動作に問題があり、ウィンドウに映像が正常に表示出来なかったりしました。
そこで、 " Launchpad " に登録されているPPA (Personal Package Archive)の1つである " Thanh Tung Nguyen " さんの " rebuntu16 " というPPAを自分の環境に追加し、Ubuntu 14.04 LTSでビルド済みの " Avidemux " をインストール致しました。
インストールしたのは " avidemux2.6-qt4 " です。
" Thanh Tung Nguyen " さんのPPAのURL:
https://launchpad.net/~rebuntu16
これで長らく快適に動画編集していたのですが、私の環境に於いて、最近のアップデートで動画ファイルを開く時にエラーが出て開けなくなってしまいました。更に新しいアップデートではアップデート中にエラーが出てアップデート不能になってしまいました。
そこで一旦このソフトウェアを " 端末 " から " sudo apt-get purge avidemux2.6-qt4 " として削除した後、 " sudo apt-get autoclean " 、 " sudo apt-get clean " 、 " sudo apt-get -f install " 、 " sudo apt-get autoremove " を実行しました。
私が何か不適切なパッケージ名を入力したりしたのかもしれませんが、再インストール時に依存関係の問題や競合が発生してしまいました。
その後、 " apt-get " の代わりにより高機能なパッケージ管理機能のフロントエンドである " aptitude " を " sudo apt-get install aptitude " としてインストールしてこれを用いてAvidemuxをインストール致しました。
" sudo aptitude install avidemux2.6-qt4 " を実行したところ、正常にインストールする事が出来ました。
インストールされたヴァージョンは " Avidemux 2.6.12 (Qt4) " です。
インストールされた " avidemux2.6-qt4 " を実行したところ、正常に動画ファイルを開く事が出来ました。
ところで、映像にフィルター処理等を施した場合等は再圧縮せざるを得ませんので、この様な場合には私はオープンソースで無料の優れた映像編集ソフトウェアである " OpenShot Video Editor " を使用しております。
"OpenShot Video Editor" の公式ウェブサイトのURL:
http://www.openshot.org/
初心者の方向けに、 " PPA " については次のページが参考になります。
"All About" の記事 "UbuntuのPPAて何?" のURL:
http://allabout.co.jp/gm/gc/438675/
プログラム生成画像 [ソフトウェア]
私は先日、乱数を元にして大量の斑模様の画像を作り出し、ニューラル ネットワークに学習させようとしておりました。しかしながら、画像の生成等にどうにも時間が掛り過ぎてしまう事、ストレージを消費し過ぎる事、ランダムな模様の中にも思想的に象徴的な図形がある程度出てしまう事等から、実験を断念する事に致しました。
進化型画像生成ソフトウェアの "Evolvotron" で作った画像。 [ソフトウェア]
先日、人工ニューラル ネットワークで多数の画像を学習して素晴らしい画質で画像を拡大したりノイズ低減したり出来るプログラムである " waifu2x " について記事を書きました。
ブログ記事: 最高峰の学習型画像拡大ソフトウェアを使ってみました。
http://crater.blog.so-net.ne.jp/2015-11-26
その中で、学習用の画像データ セットは全て私が " Evolvotron " というアプリケーション ソフトウェアを用いて自動生成したものを使用したと述べました。
この、 " Evolvotron " というソフトウェアは、プログラムが自動的に生成した多数の模様の中から自分の好みのものを選ぶと、他の画像について新たにそれに近いパラメーターを持つ画像に変異(Mutate)させます。
これを繰り返して行くと数世代後には、より自分好みの絵柄が得られるという訳です。
"Evolvotron" の公式ウェブサイトのURL:
http://www.bottlenose.net/share/evolvotron/
" waifu2x " 及び " Evolvotron " については先日の記事をご覧いただくとして、今回はそのEvolvotronに生成させた画像を掲載させて頂きます。
生成画像の大きさは、2048 x 2048[pixels]です。

https://c1.staticflickr.com/1/713/23307011139_f803570cce_o.png

https://c1.staticflickr.com/1/732/23674973725_a74673a73d_o.png

https://c2.staticflickr.com/6/5719/23379300570_d4c8782812_o.png
https://c1.staticflickr.com/1/586/23307009709_0bed7066d1_o.png

https://c1.staticflickr.com/1/584/23379299660_40c3e1d48d_o.png

https://c2.staticflickr.com/6/5771/23046805494_786f2b1a31_o.png

https://c1.staticflickr.com/1/735/23648880226_d302a2deeb_o.png

https://c2.staticflickr.com/6/5801/23307007729_395b075366_o.png
https://c1.staticflickr.com/1/645/23592502051_f86dc96b36_o.png

https://c1.staticflickr.com/1/645/23674970235_511eefe8de_o.png

https://c2.staticflickr.com/6/5787/23379297560_42c9498709_o.png

https://c2.staticflickr.com/6/5658/23379297200_413fddb645_o.png

https://c1.staticflickr.com/1/759/23566407422_43fbed9cd6_o.png
https://c2.staticflickr.com/6/5823/23592499481_1ebce00337_o.png

https://c1.staticflickr.com/1/746/23648876656_3989c857c3_o.png

https://c2.staticflickr.com/6/5809/23047900293_ee24dfb075_o.png

https://c1.staticflickr.com/1/573/23046801174_69b83d0227_o.png

https://c1.staticflickr.com/1/699/23674966985_5e188c8932_o.png

https://c2.staticflickr.com/6/5674/23379294000_b62d3a3355_o.png
そして、生成した画像を " XnConvert " というソフトウェアで一括処理で " エンボス(強) " 加工すると、以下の様になります。

https://c2.staticflickr.com/6/5623/23592517401_f4c4089953_o.png

https://c2.staticflickr.com/6/5831/23566423182_a75a91bc8b_o.png

https://c2.staticflickr.com/6/5654/23566422222_b2d9b9971a_o.png

https://c1.staticflickr.com/1/772/23047915023_3d39592779_o.png

https://c1.staticflickr.com/1/645/23648886906_4a42f3dac7_o.png

https://c1.staticflickr.com/1/779/23307014069_b665ff8982_o.png

https://c2.staticflickr.com/6/5652/23566414492_5802be1d21_o.png

https://c2.staticflickr.com/6/5779/23566413232_e3e1c729a2_o.png
ブログ記事: 最高峰の学習型画像拡大ソフトウェアを使ってみました。
http://crater.blog.so-net.ne.jp/2015-11-26
その中で、学習用の画像データ セットは全て私が " Evolvotron " というアプリケーション ソフトウェアを用いて自動生成したものを使用したと述べました。
この、 " Evolvotron " というソフトウェアは、プログラムが自動的に生成した多数の模様の中から自分の好みのものを選ぶと、他の画像について新たにそれに近いパラメーターを持つ画像に変異(Mutate)させます。
これを繰り返して行くと数世代後には、より自分好みの絵柄が得られるという訳です。
"Evolvotron" の公式ウェブサイトのURL:
http://www.bottlenose.net/share/evolvotron/
" waifu2x " 及び " Evolvotron " については先日の記事をご覧いただくとして、今回はそのEvolvotronに生成させた画像を掲載させて頂きます。
生成画像の大きさは、2048 x 2048[pixels]です。
https://c1.staticflickr.com/1/713/23307011139_f803570cce_o.png
https://c1.staticflickr.com/1/732/23674973725_a74673a73d_o.png
https://c2.staticflickr.com/6/5719/23379300570_d4c8782812_o.png
https://c1.staticflickr.com/1/586/23307009709_0bed7066d1_o.png
https://c1.staticflickr.com/1/584/23379299660_40c3e1d48d_o.png
https://c2.staticflickr.com/6/5771/23046805494_786f2b1a31_o.png
https://c1.staticflickr.com/1/735/23648880226_d302a2deeb_o.png
https://c2.staticflickr.com/6/5801/23307007729_395b075366_o.png
https://c1.staticflickr.com/1/645/23592502051_f86dc96b36_o.png
https://c1.staticflickr.com/1/645/23674970235_511eefe8de_o.png
https://c2.staticflickr.com/6/5787/23379297560_42c9498709_o.png
https://c2.staticflickr.com/6/5658/23379297200_413fddb645_o.png
https://c1.staticflickr.com/1/759/23566407422_43fbed9cd6_o.png
https://c2.staticflickr.com/6/5823/23592499481_1ebce00337_o.png
https://c1.staticflickr.com/1/746/23648876656_3989c857c3_o.png
https://c2.staticflickr.com/6/5809/23047900293_ee24dfb075_o.png
https://c1.staticflickr.com/1/573/23046801174_69b83d0227_o.png
https://c1.staticflickr.com/1/699/23674966985_5e188c8932_o.png
https://c2.staticflickr.com/6/5674/23379294000_b62d3a3355_o.png
そして、生成した画像を " XnConvert " というソフトウェアで一括処理で " エンボス(強) " 加工すると、以下の様になります。
https://c2.staticflickr.com/6/5623/23592517401_f4c4089953_o.png
https://c2.staticflickr.com/6/5831/23566423182_a75a91bc8b_o.png
https://c2.staticflickr.com/6/5654/23566422222_b2d9b9971a_o.png
https://c1.staticflickr.com/1/772/23047915023_3d39592779_o.png
https://c1.staticflickr.com/1/645/23648886906_4a42f3dac7_o.png
https://c1.staticflickr.com/1/779/23307014069_b665ff8982_o.png
https://c2.staticflickr.com/6/5652/23566414492_5802be1d21_o.png
https://c2.staticflickr.com/6/5779/23566413232_e3e1c729a2_o.png
最高峰の学習型画像拡大ソフトウェアを使ってみました。 [ソフトウェア]
->->
[2018年12月28日追記]
2018年12月28日現在の最高峰の画像拡大プログラムは、SRGAN (超解像敵対的生成ネットワーク / Super-Resolution Generative Adversarial Network)及びその派生型です。
わたしは現在、このSRGANを改造して機械学習を実行して遊んでおります。
信じられないほどに自然で美しい縦横4倍の拡大ができます。
<-<-
2016年9月6日現在最高峰の画像拡大ソフトウェアはと言えば、 " waifu2x " であると言えるでしょう。
私は2015年の11月10日にwaifu2xのリポジトリーをGitHubから私のUbuntu PCにクローンして使用してみまして、私はその非常に優れた画像拡大性能にとても驚いておりました。
2016年08月18日に私は新たにwaifu2xのリポジトリーをGitHubからクローンし直しまして、改良されたwaifu2xの性能に再び驚かされたのと、自作のジェネレーティヴ アート画像による深層学習で良い結果が得られましたので、この度記事を改訂する事に致しました。

https://c1.staticflickr.com/9/8323/29416402671_97b056ff80_o.png
左から順に、自前のジェネレーティヴ アート画像群による学習済みモデル データによって " waifu2x " で2回2倍に拡大(4倍)した画像と、ランタナの花の元の写真と、 " Lanczos " で同様に拡大した画像との比較画像です。
"ultraist" 様のブログ "デー" の "Waifu2x" に関するページのURL:
http://ultraist.hatenablog.com/entry/2015/05/17/183436
githubの "Waifu2x" のディレクトリーのURL:
https://github.com/nagadomi/waifu2x
このソフトウェアは、複数層の畳み込み人工ニューラル ネットワーク(以下NN)を用いて多数の画像例から低解像度画像と高解像度画像の対応関係のパターンを学習させ、拡大させたい画像を入力すると、双三次関数補間法(Bicubic Interpolation)やランツォシュ補間法(Lanczos Resampling)等の昔から使われて来た内挿法だけでは成し得なかった高品質な高解像度画像を出力させる事が出来ます。
また、JPEG画像の中の事物の輪郭部などに見られる様なデジタル圧縮ノイズについても、同様にして圧縮ノイズを除去する事が可能です。
作者の方は大変親切な事に、ウェブ サーヴァーにてこのソフトウェアを使用できる無償のサーヴィスを提供して下さっております。
また、このソフトウェアのソースコードはgithubで公開されており、Ubuntu OS等のLinux ディストリビューションを使用しておりヴィデオ カードがNVIDIA系でCUDAが利用出来る人は直ぐにローカル環境で使用する事が出来る他、自分で学習用の画像データ セットを用意して、NNに学習させる事も出来ます。
更に動画につきましても、 " ffmpeg " などのサード パーティー製ソフトウェアを使用して動画ファイルを連続の静止画に分解する事により、waifu2xは連番の静止画を連続で拡大及びノイズ低減処理をする事が出来ますので、処理完了後に再びffmpegで動画像ファイルに書き出せば、時間は掛かりますが、もの凄く高品質な動画のアップスケーリング及びノイズ リダクションが可能です。
Windows OS環境用には既存の学習済みデータを用いるGUIのアプリケーション ソフトウェアが作られているようです。
更に、動画編集時のフレーム サーヴァーとして有名な " AviSynth " にも組み込む事が出来るプラグインも開発されているようです。
私は、P2P分散型ウェブ検索エンジンである " YaCy " や、自作天体望遠鏡で月を撮影した高画素数の画像データを多数枚自動で位置揃えと幾何学変形と合成をして高解像度化する為に使用するアプリケーション ソフトウェアである " AviStack2 " の為にUbuntu PCに、32[GB]のDDR3 SDRAM メイン メモリーを搭載してあります。
"YaCy" に関する私のブログ記事:
http://crater.blog.so-net.ne.jp/archive/c2305456728-1
月の撮影画像の合成に関する私のブログ記事: UbuntuでAviStack2により月画像処理をする。
http://crater.blog.so-net.ne.jp/2014-09-22
waifu2xの使用方法は添付ファイルに書いてある通りで実に簡単でした。
githubの "Waifu2x" の "README" ファイルのURL:
https://github.com/nagadomi/waifu2x/blob/master/README.md
2016年09月06日現在の私のPC環境は以下の通りです。
OS: Ubuntu 16.04 LTS
Architecture: x86_64
Linux Kernel: 4.4.0
Video Card: GeForce GTX750
Graphics Driver: NVIDIA binary driver version 361.45.18 (Open Source)
Main Memory: DDR3 SDRAM 32GB
私はGitHubから最新の " waifu2x " のリポジトリーをクローンし直すに当たり、まず、waifu2x及びTorch7を一旦削除致しました。
NVIDIAのGPUによる汎用コンピューティング環境であるCUDAにつきましても再び導入致しました。
まだCUDAをインストールしていない方はこれをインストールする必要がございます。
まずはNVIDIAのウェブサイトにアクセスして、私のPCはCPUがIntel Core-i7 3770TでOSは64bit版なので以下の様に環境を選択致しました。
Operating System: Linux
Architecture: x86_64
Distribution: Ubuntu
Version: 14.04
Installer Type: deb(local)
そしてCUDAの .deb パッケージ ファイルをダウンロード致しました。
2016年08月18日時点ではCUDAの正式なリリースはヴァージョン 7.5までであり、Ubuntu 16.04 LTS版は用意されていなかったので、 Ubuntu 14.04版をダウンロード致しました。
また、2016年08月18日時点ではUbuntu 16.04 LTSには、 " GCC (GNU Compiler Collection) 5.4 " がインストールされておりますが、CUDA 7.5は gcc 4.9よりも新しいヴァージョンのgccは正式にサポートされておらず、waifu2xに必要なTorch7のインストール用のシェル スクリプト実行時にビルド エラーとなります。
" unsupported GNU version! gcc versions later than 4.9 are not supported! " と表示されました。
そこで、仕方無く強制的にgcc 5.4を使用させるようにする為、設定ファイルの中のエラー処理部分をコメント アウト致しました。詳しくは当記事内で後述致します。
"NVIDIA" のウェブサイトの "CUDA" のダウンロード ページのURL:
https://developer.nvidia.com/cuda-downloads
" 端末 " から以下のコマンドを実行致しました。
" xxxx/cuda-xxxxxxxxxxx.deb " のパスとファイル名は各自のものを入力致します。
私が一番苦労したのは実はNVIDIAのCUDAの使用許諾契約書を読む事でした。
私はEnglishはとても苦手なのでGoogle翻訳サーヴィスで日本語に訳しながら目を通しました。
それでも読み終えるまでに長い時間が掛かりました。
次に、圧縮/展開プログラムのライブラリーである " Snappy " をインストール致しました。
続いて、Facebookがgithubで公開している、NN コンピューティング フレームワークである " Torch7 " を導入致しました。
技術系メディアである "TechCrunch Japan" のウェブサイトの "Torch7" 関連の記事ページのURL:
http://jp.techcrunch.com/2015/01/17/20150116facebook-open-sources-some-of-its-deep-learning-tools/
私はwaifu2xを最新版にするに当たり、下記のコマンドでTorch7を一旦削除致しました。
そして説明の通りに、Torch7のgit リポジトリーをクローンしました。
また、 " Lua " モジュール パッケージ管理ツールの " LuaRocks " もインストールされます。
因みにTorch7のインストールの処理が終わるまでには少々時間が掛かりました。
"Torch7" の導入に関するウェブ ページのURL:
http://torch.ch/docs/getting-started.html
まずはTorch7をGitHubからクローンし、Torch7が必要とする諸々のものをインストール致します。
先にも述べました通り、2016年08月18日時点ではUbuntu 16.04 LTSには、 " GCC (GNU Compiler Collection) 5.4 " がインストールされておりますが、CUDA 7.5は gcc 4.9よりも新しいヴァージョンのgccは正式にサポートされておらず、waifu2xに必要なTorch7のインストール用のシェル スクリプト実行時にビルド エラーとなります。
" unsupported GNU version! gcc versions later than 4.9 are not supported! " と表示されました。
そこで、仕方無く強制的にgcc 5.4を使用させるようにする為、下記の様に設定ファイルの中のエラー処理部分をコメント アウト致しました。
この方法は以下のウェブサイトに記載されていた情報です。
"Puget Custom Computers" の記事 "NVIDIA CUDA with Ubuntu 16.04 beta on a laptop (if you just cannot wait)" のURL:
https://www.pugetsystems.com/labs/hpc/NVIDIA-CUDA-with-Ubuntu-16-04-beta-on-a-laptop-if-you-just-cannot-wait-775/
警告: この用法を実行する事による危険性に関しては私は承知致しません。 私はこの方法を実行した事によって生じるいかなる損害も補償出来ません。 全てはあなた自身の責任の下に判断して下さい。
/usr/local/cuda/include/host_config.h
上記ファイルの中の該当箇所を下記のように先頭に " // " を付け足してコメント アウト致しました。
そして、Torch7のインストール用のシェル スクリプトを実行致します。
これで問題無くビルドに成功致しました。
上記のコマンドを実行したら、 " ~/.bashrc " と " ~/.profile " の最後に次の行が追加されました。
尚、 " xxxxxx " には各自のユーザー名が入ります。 " ~ " はホーム ディレクトリーを表します。
追加された行の最初にある " . " は " source " コマンドと同じ意味を持ち、引数に指定したファイルに書かれている文字列を実行するものだそうです。
ここで、次のコマンドを実行する事で、ログインし直さずに " torch-activate " が実行されます。
次回のログイン時からは上記のコマンドの実行は不要です。
" 端末 " から次のコマンドを実行して、 " 端末 " に " Torch " のロゴマークが表示されれば正常に使用出来る状態です。
必要があるか、また記述の仕方が正しいかどうかは存じませんが、 " ホーム ディレクトリー " にある " .profile " を編集して以下の行をファイルの最後に追記する事により、環境変数を設定致しました。
私は " CUDA 7.5 " をインストールしたので環境変数のパスに " cuda-7.5 " と書きましたが、各自の環境に合った名前に致します。
各々のパスは " : "(コロン) で区切られます。
" PATH= " で " PATH " という変数に値を代入します。
" LD_LIBRARY_PATH= " で " LD_LIBRARY_PATH " という変数に値を代入します。
" $PATH " 及び " $LD_LIBRARY_PATH " は既存のパスを表します。
" export " でパスを出力して環境変数を設定します。
" .profile " はUbuntuではユーザーのログイン時に読み込まれるファイルであると私は認識しております。
只、既に " torch-activate " が実行されているのですから、改めて " Torch " のパスを設定する必要は無いのかもしれません。
余談ですが、Linuxでは一般的にシェルに " bash " が使われているところ、Ubuntuではログイン シェルについては " bash " ですが、その他は " dash " が使われているそうです。
シェルやGUI、CUI、ファイル マネージャー、ログイン、端末、TTY、daemon等について、解り易く解説してくれているウェブ ページを勝手ながら紹介させて頂きます。
ブログ "主に言語とシステム開発に関して" の記事ページ "Linux上でシェルが実行される仕組みを,体系的に理解しよう (bash 中級者への道)" のURL:
http://language-and-engineering.hatenablog.jp/entry/20110617/p1
次に、必要な " LuaRocks " パッケージをインストール致しました。
説明ページに記載があった " Turbo " は、ウェブ アプリケーション関係のものですが、私はそれには関わらないので、これについてはインストール致しませんでした。
最後に、 " waifu2x " のgit リポジトリーをクローン致しました。
ここで、早速 " waifu2x " を試してみます。
" 端末 " で次のコマンドを実行致します。
しかし、画像処理プログラムである " GraphicsMagick " がインストールされていない場合はエラー メッセージが出ます。
~/waifu2x$ th waifu2x.lua
gm (GraphicsMagick) binary not found, please install (see www.graphicsmagick.org)
images/miku_small(noise_scale).png: 1.1321530342102 sec
この場合は下記の様にして " GraphicsMagick " をインストールします。
これで正常に動作する筈です。
これで準備が整いましたので、まずは添付されていた学習済みデータを用いて任意の画像の拡大を試してみました。
2倍の寸法にする拡大ですが、非常に素晴らしい画質でした。
以下のコマンドは作業ディレクトリーを " ~/waifu2x/ " としてあります。
" input_image " は拡大対象の画像ファイルのパスとファイル名を入力します。
" output_image " は保存する際の画像ファイルのパスとファイル名を入力します。
[レヴェル1のノイズ除去 + 2倍に拡大]
次に、自前の画像データ セットで人工ニューラル ネットワークに学習させる事を試みました。
私は学習用画像データ セットとして、自作のHTML5のCanvas要素とJavaScriptによってジェネレーティヴ アート画像を大量に自動生成させたものだけを使用致しました。
乱数による自動生成画像です。
自作のジェネレーティヴ アート画像自動生成プログラムは下記の " Yahoo!ボックス " にアップロードして公開しております。
御興味がございましたら、どうぞ御自由にお使い下さい。
使い方は簡単で、ダウンロードしたHTML ファイルをFirefoxなどHTML5対応のウェブ ブラウザーで開き、ブラウザーの設定で " .png " 形式の画像ファイルのダウンロード時にダイアログを表示させないようにした上で、 " Play / Stop " ボタンをクリックするだけです。
すると、自動生成された画像が10秒毎にPNG形式のファイルとしてブラウザーで設定されているダウンロード ディレクトリーに次々と2048枚までダウンロードされます。
ダウンロードし終わったら、セキュリティーを維持する為に必ずブラウザーのダウンロード設定を元に戻して下さい。
[Yahoo!ボックス]
http://yahoo.jp/box/4_Sq4x

https://c1.staticflickr.com/9/8199/28872340824_fe7e8fc4a7_o.png
自作のジェネレーティヴ アート画像自動生成プログラムが生成した大量のディジタル アートの1枚です。

https://c1.staticflickr.com/9/8171/29208180350_099d57a5fc_o.png
これらの画像を大量に学習させました。
尚この画像生成プログラムは、自作インタラクティヴ ディジタル アート プログラムから派生させたプログラムです。
基となったプログラムに関する私のブログ記事: HTML5のCamvasと "JavaScript" で音声処理と画像描画。
http://crater.blog.so-net.ne.jp/2016-06-30
因みに、初めwaifu2xを2048枚で学習させた後に、512枚を追加して " -resume " オプションで追加学習させるといった事も出来ました。
私は生成させた画像2048枚+512枚を " XnConvert " という一括画像処理が出来るフリー ソフトウェアで自動コントラスト調整し、waifu2xで学習させました。
尚、このプログラムで生成した画像データを用いて学習させたwaifu2xのモデルは充分に素晴らしい画質で拡大、ノイズ リダクションが出来ました。
"XnConvert" の公式ウェブサイトのURL:
http://www.xnview.com/en/xnconvert/
ところで、私が学習用画像データ セットをジェネレーティヴ アート画像だけにした理由は、例えば実写の写真に写り込んでいる色々の嫌なもの、汚いものをNNに見せて学習させた結果が適用されるのが嫌だからです。
もし、綺麗な女性のポートレート写真を拡大した際に、睫毛の拡大処理に厳つい男性の髭で学習されたパラメーターが使われていたら嫌だなあと、感覚的な問題ですが、私はそう思ったのです。
その為に以前、フラクタル画像やカオス図形を生成するアプリケーション ソフトウェア等を中心に幾つも試したのですが、フラクタル図形は2D、3D共に、大きな構造から始まって際限無く微細な構造が描かれて行く為細部がノイズになってしまう欠点があり、カオス図形という枠組みで見ても線描画や点描画が多く、最適なものは中々見つかりませんでした。
次に " Evolvotron " というアプリケーション ソフトウェアを試しました。
"Evolvotron" の公式ウェブサイトのURL:
http://www.bottlenose.net/share/evolvotron/
" Ubuntuソフトウェアセンター " からインストール致しました。
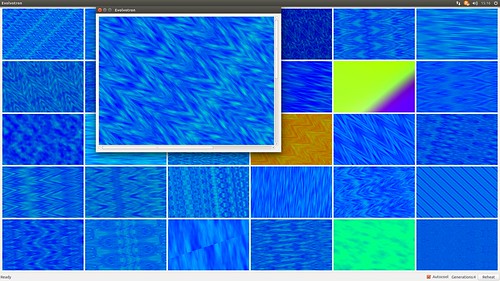
https://c1.staticflickr.com/1/674/23257755171_2a391b2cec_o.png
プログラムによって作られる幾つもの様式の図形、模様を組み合わせて画像を生成し、乱数のパラメーターによってそれが様々に変化します。
このソフトウェアはGUIで使用出来、メインのウィンドウには横6列、縦5行のランダムに生成された画像が小さく並んでおります。
ユーザーは、この中から好きなパターンを選んでクリックします。
すると、他の画像が、選んだ画像のパラメーターを元にして、変異(Mutate)した画像に置き換わります。
" Autocool " オプションにチェック マークを付けた状態で、これを繰り返して行くと、ユーザーの好みの画像へと収斂して行き、満足の行く作品が出来上がるのです。
途中で、 " Lock " して幾つかの画像を保持する事も出来、また、パラメーターのリセットや、パラメーターのファイルへの書き出しと読み込みも簡単に出来ます。
好みの画像は大きさを選んで別ウィンドウに大きく表示する事が出来ます。
コンテキスト メニューから保存が出来ます。
レンダリングのオプションとして、 " Oversampling (antialiasing) " で輪郭等を滑らかにしたり、 " Jitterd samples " でグラデーションにジッターを加えて、ざらつきを軽減したり出来ます。
実際にどの様な画像を生成したのかにつきましては、次の記事をご覧下さい。
ブログ記事: 進化型画像生成ソフトウェアの "Evolvotron" で作った画像。
http://crater.blog.so-net.ne.jp/2015-11-30
このEvolvotronというソフトウェアが生成した画像もそこそこ良かったのですが、私は更に、乱数だけに基づいた単一のアルゴリズムによる画像群だけで学習させたく思い、HTML5のCanvas要素とJavaScriptによってこれを実現する為に前述の自作プログラムを作成したのです。
そして大量の学習用画像データ セットが用意出来ました。
これにて漸く学習の準備が整いました。
" 端末 " からCUIで学習を行わせます。
以下のコマンドは作業ディレクトリーを " ~/waifu2x/ " としてあります。
" input_image " は拡大対象の画像ファイルのパスとファイル名を入力します。
" output_image " は保存する際の画像ファイルのパスとファイル名を入力します。
[学習済みデータ格納用ディレクトリーの作成]
[学習用画像リスト作成]
" xxxxx " の部分は各自の学習用画像ファイルがあるフォルダーのパスを入力します。
パスに半角スペースが含まれる場合等はパス全体をシングル クォーテーション記号で括ります。
[学習用データ変換]
続きまして、実際の学習処理を行いました。
[2倍拡大用の学習]
[2倍拡大 + 圧縮ノイズ低減処理用の学習]
ここで、 " Reference_1.png " は私が用意した画像ファイルです。
各自任意の画像ファイルを指定して下さい。
学習が進み、モデル データが更新される度に、 " /models/my_model/ " に指定した画像を拡大した結果が保存され、性能を確認出来ます。
" 2倍拡大 + ノイズ低減処理用の学習 " のコマンドの引数にある " -nr_rate 0.9 " はノイズ低減処理の強さです。
値が大きい程ノイズを消しますが、同時に細部の情報が失われてしまいます。
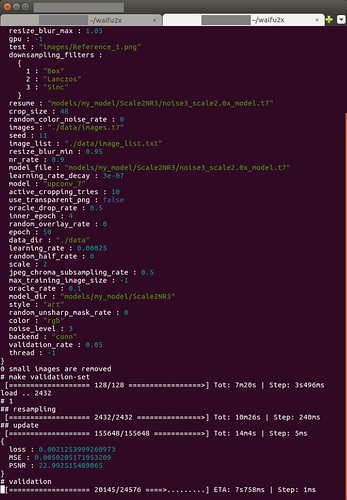
上記のコマンドを実行し、Ubuntuのシステム モニターでCPUとメモリーの使用率を見ていたところ、メイン メモリーは僅か12.1[GiB]程しか使用しておりませんでした。CPUはマルチスレッドで全稼働か、シングル スレッドで使用率100[%]となっておりました。
因みに初期のwaifu2xはより多くのメイン メモリーを使用しておりました。
改良によりメイン メモリーの使用率を低減出来たようです。
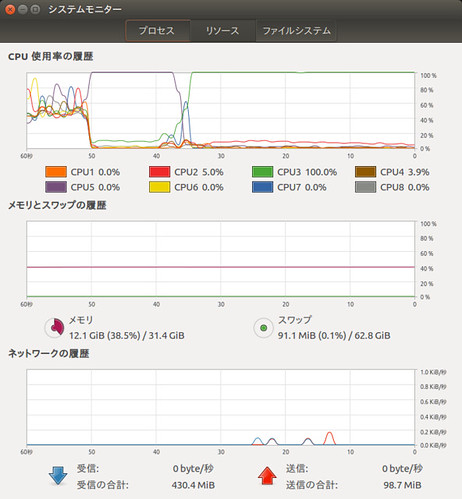
上記のコマンドを実行すると、画像ファイル数の1/20の数の評価用データ セットが作られるようです。
引数で指定せず、初期設定では内部4世代 x 50世代の合計200回の反復処理が行われます。
1世代毎に学習と評価が行われ、評価が過去最高であればモデル データが更新されます。
画面には " loss " , " MSE ", " PSNR " が表示されます。
" MSE " とは " Mean Squared Error " の事で、 " 平均平方誤差 " と言います。
簡略化して述べると、基準用の高解像度画像と、処理した結果の画像との間の差分を取り、これを2乗して平均値を出した値の事だそうです。
処理が上手く行って基準用画像に近付く程、MSEの値は小さくなり、0に近付きます。
PSNR (Peak Signal-to-Noise Ratio / ピーク信号対雑音比)はMSEの値から計算されるそうです。
尚、誤差をRMS(Root Mean Square / 二乗平均平方根)としてRMS Errorとする場合も多いようです。
このMSEやPSNRの値は、学習が進む毎に徐々に変化し難くなって行きます。
また、値を更新させる割合である " learning rate decay " も指数関数的に小さくなっていきます。
私は以前、自作天体望遠鏡とコンパクト ディジタル カメラで撮影した月の画像を合成処理した際は処理完了までに約1週間掛かりましたが、今回の機械学習は僅か1日間で済みました。
上記の処理で学習(トレーニング)は完了です。
次は学習済みモデル データを使用した画像処理です。
以下のコマンドは作業ディレクトリーを " ~/waifu2x/ " としてあります。
" input_image " は拡大対象の画像ファイルのパスとファイル名を入力します。
" output_image " は保存する際の画像ファイルのパスとファイル名を入力します。
[学習させたモデル データによる2倍拡大]
[学習させたモデル データによる2倍拡大 + 圧縮ノイズ低減処理]
学習が終わった畳み込み人工ニューラル ネットワークによる画像の拡大結果は非常に素晴らしいものでした。
どんな種類の画像でも元からその解像度だったのではないかと思える程綺麗に拡大出来ております。
コンピューター生成画像だけを使った学習実験は大成功でした。
以下に使用前後の比較画像を載せますが、ブログ内では縮小表示されているので、画像下のURLからオリジナルのファイルをご覧下さい。

https://c1.staticflickr.com/9/8340/28871566744_76f7899b1d_o.png
左から順に、自前のジェネレーティヴ アート画像群による学習済みモデル データによって " waifu2x " で2回2倍に拡大(4倍)した画像と、ランタナの花の元の写真と、 " Lanczos " で同様に拡大した画像との比較画像です。
https://c1.staticflickr.com/9/8323/29416402671_97b056ff80_o.png
こちらは記事の最初に掲載した比較用の画像です。
Lanczos補間法によるものと比べて輪郭は鋭利であり、また、アンダーシュートとオーヴァーシュートが無くて綺麗です。
" waifu2x " の作者様、及び、関係するプログラム等の作者様方には心より感謝申し上げます。
本当にありがとうございます。
ところで、拡大の他にもし、不鮮明なぼやけた画像を鮮明にしたい場合には他の何らかのソフトウェアを用いて " Iterative Deconvolution " という処理をするのが効果的です。
オープン ソース ソフトウェアの " GIMP " という画像編集ソフトウェアに " G'MIC - GREYC's Magic for Image Computing " というプラグインがございまして、これの機能の1つに " Iterative Deconvolution " がございます。
" GIMP 2.9.5 "内のメニュー項目は " Filters " - " G'MIC... " - " Details " - " Sharpen [richardson-lucy] " となっております。
これを使用するのが最も簡単であるかと存じます。
"GIMP" の公式ウェブサイトのURL:
http://www.gimp.org/
"G'MIC" のウェブサイトのGIMP プラグインのページのURL:
http://gmic.eu/gimp.shtml
更に、点拡がり関数の画像を自前で用意して様々なメソッドを使えるという点で、Java VM上で動作するオープン ソース ソフトウェアの " ImageJ " にプラグインを導入したものも便利だと思います。
" ImageJ " は医療や生物学等の研究者が使用する事が多いようです。
"ImageJ" の公式ウェブサイトのURL:
http://imagej.nih.gov/ij/
Gaussian_PSF_3D.class:
ガウス関数型点拡がり関数の画像スタックを作るプラグインです。
http://www.optinav.com/Convolve_3D.htm
Iterative_Deconvolution.class:
反復型の、コンヴォリューションとデコンヴォリューションの為のプラグインです。
http://www.optinav.com/Iterative-Deconvolution.htm
Iterative_Deconvolve_3D.class:
2Dと3Dの非負の反復型のデコンヴォリューションの為のプラグインです。
http://www.optinav.com/Iterative-Deconvolve-3D.htm
[2018年12月28日追記]
2018年12月28日現在の最高峰の画像拡大プログラムは、SRGAN (超解像敵対的生成ネットワーク / Super-Resolution Generative Adversarial Network)及びその派生型です。
わたしは現在、このSRGANを改造して機械学習を実行して遊んでおります。
信じられないほどに自然で美しい縦横4倍の拡大ができます。
<-<-
2016年9月6日現在最高峰の画像拡大ソフトウェアはと言えば、 " waifu2x " であると言えるでしょう。
私は2015年の11月10日にwaifu2xのリポジトリーをGitHubから私のUbuntu PCにクローンして使用してみまして、私はその非常に優れた画像拡大性能にとても驚いておりました。
2016年08月18日に私は新たにwaifu2xのリポジトリーをGitHubからクローンし直しまして、改良されたwaifu2xの性能に再び驚かされたのと、自作のジェネレーティヴ アート画像による深層学習で良い結果が得られましたので、この度記事を改訂する事に致しました。
https://c1.staticflickr.com/9/8323/29416402671_97b056ff80_o.png
左から順に、自前のジェネレーティヴ アート画像群による学習済みモデル データによって " waifu2x " で2回2倍に拡大(4倍)した画像と、ランタナの花の元の写真と、 " Lanczos " で同様に拡大した画像との比較画像です。
"ultraist" 様のブログ "デー" の "Waifu2x" に関するページのURL:
http://ultraist.hatenablog.com/entry/2015/05/17/183436
githubの "Waifu2x" のディレクトリーのURL:
https://github.com/nagadomi/waifu2x
このソフトウェアは、複数層の畳み込み人工ニューラル ネットワーク(以下NN)を用いて多数の画像例から低解像度画像と高解像度画像の対応関係のパターンを学習させ、拡大させたい画像を入力すると、双三次関数補間法(Bicubic Interpolation)やランツォシュ補間法(Lanczos Resampling)等の昔から使われて来た内挿法だけでは成し得なかった高品質な高解像度画像を出力させる事が出来ます。
また、JPEG画像の中の事物の輪郭部などに見られる様なデジタル圧縮ノイズについても、同様にして圧縮ノイズを除去する事が可能です。
作者の方は大変親切な事に、ウェブ サーヴァーにてこのソフトウェアを使用できる無償のサーヴィスを提供して下さっております。
また、このソフトウェアのソースコードはgithubで公開されており、Ubuntu OS等のLinux ディストリビューションを使用しておりヴィデオ カードがNVIDIA系でCUDAが利用出来る人は直ぐにローカル環境で使用する事が出来る他、自分で学習用の画像データ セットを用意して、NNに学習させる事も出来ます。
更に動画につきましても、 " ffmpeg " などのサード パーティー製ソフトウェアを使用して動画ファイルを連続の静止画に分解する事により、waifu2xは連番の静止画を連続で拡大及びノイズ低減処理をする事が出来ますので、処理完了後に再びffmpegで動画像ファイルに書き出せば、時間は掛かりますが、もの凄く高品質な動画のアップスケーリング及びノイズ リダクションが可能です。
Windows OS環境用には既存の学習済みデータを用いるGUIのアプリケーション ソフトウェアが作られているようです。
更に、動画編集時のフレーム サーヴァーとして有名な " AviSynth " にも組み込む事が出来るプラグインも開発されているようです。
私は、P2P分散型ウェブ検索エンジンである " YaCy " や、自作天体望遠鏡で月を撮影した高画素数の画像データを多数枚自動で位置揃えと幾何学変形と合成をして高解像度化する為に使用するアプリケーション ソフトウェアである " AviStack2 " の為にUbuntu PCに、32[GB]のDDR3 SDRAM メイン メモリーを搭載してあります。
"YaCy" に関する私のブログ記事:
http://crater.blog.so-net.ne.jp/archive/c2305456728-1
月の撮影画像の合成に関する私のブログ記事: UbuntuでAviStack2により月画像処理をする。
http://crater.blog.so-net.ne.jp/2014-09-22
waifu2xの使用方法は添付ファイルに書いてある通りで実に簡単でした。
githubの "Waifu2x" の "README" ファイルのURL:
https://github.com/nagadomi/waifu2x/blob/master/README.md
2016年09月06日現在の私のPC環境は以下の通りです。
OS: Ubuntu 16.04 LTS
Architecture: x86_64
Linux Kernel: 4.4.0
Video Card: GeForce GTX750
Graphics Driver: NVIDIA binary driver version 361.45.18 (Open Source)
Main Memory: DDR3 SDRAM 32GB
私はGitHubから最新の " waifu2x " のリポジトリーをクローンし直すに当たり、まず、waifu2x及びTorch7を一旦削除致しました。
NVIDIAのGPUによる汎用コンピューティング環境であるCUDAにつきましても再び導入致しました。
まだCUDAをインストールしていない方はこれをインストールする必要がございます。
まずはNVIDIAのウェブサイトにアクセスして、私のPCはCPUがIntel Core-i7 3770TでOSは64bit版なので以下の様に環境を選択致しました。
Operating System: Linux
Architecture: x86_64
Distribution: Ubuntu
Version: 14.04
Installer Type: deb(local)
そしてCUDAの .deb パッケージ ファイルをダウンロード致しました。
2016年08月18日時点ではCUDAの正式なリリースはヴァージョン 7.5までであり、Ubuntu 16.04 LTS版は用意されていなかったので、 Ubuntu 14.04版をダウンロード致しました。
また、2016年08月18日時点ではUbuntu 16.04 LTSには、 " GCC (GNU Compiler Collection) 5.4 " がインストールされておりますが、CUDA 7.5は gcc 4.9よりも新しいヴァージョンのgccは正式にサポートされておらず、waifu2xに必要なTorch7のインストール用のシェル スクリプト実行時にビルド エラーとなります。
" unsupported GNU version! gcc versions later than 4.9 are not supported! " と表示されました。
そこで、仕方無く強制的にgcc 5.4を使用させるようにする為、設定ファイルの中のエラー処理部分をコメント アウト致しました。詳しくは当記事内で後述致します。
"NVIDIA" のウェブサイトの "CUDA" のダウンロード ページのURL:
https://developer.nvidia.com/cuda-downloads
" 端末 " から以下のコマンドを実行致しました。
|
" xxxx/cuda-xxxxxxxxxxx.deb " のパスとファイル名は各自のものを入力致します。
私が一番苦労したのは実はNVIDIAのCUDAの使用許諾契約書を読む事でした。
私はEnglishはとても苦手なのでGoogle翻訳サーヴィスで日本語に訳しながら目を通しました。
それでも読み終えるまでに長い時間が掛かりました。
次に、圧縮/展開プログラムのライブラリーである " Snappy " をインストール致しました。
|
続いて、Facebookがgithubで公開している、NN コンピューティング フレームワークである " Torch7 " を導入致しました。
技術系メディアである "TechCrunch Japan" のウェブサイトの "Torch7" 関連の記事ページのURL:
http://jp.techcrunch.com/2015/01/17/20150116facebook-open-sources-some-of-its-deep-learning-tools/
私はwaifu2xを最新版にするに当たり、下記のコマンドでTorch7を一旦削除致しました。
|
そして説明の通りに、Torch7のgit リポジトリーをクローンしました。
また、 " Lua " モジュール パッケージ管理ツールの " LuaRocks " もインストールされます。
因みにTorch7のインストールの処理が終わるまでには少々時間が掛かりました。
"Torch7" の導入に関するウェブ ページのURL:
http://torch.ch/docs/getting-started.html
まずはTorch7をGitHubからクローンし、Torch7が必要とする諸々のものをインストール致します。
|
先にも述べました通り、2016年08月18日時点ではUbuntu 16.04 LTSには、 " GCC (GNU Compiler Collection) 5.4 " がインストールされておりますが、CUDA 7.5は gcc 4.9よりも新しいヴァージョンのgccは正式にサポートされておらず、waifu2xに必要なTorch7のインストール用のシェル スクリプト実行時にビルド エラーとなります。
" unsupported GNU version! gcc versions later than 4.9 are not supported! " と表示されました。
そこで、仕方無く強制的にgcc 5.4を使用させるようにする為、下記の様に設定ファイルの中のエラー処理部分をコメント アウト致しました。
この方法は以下のウェブサイトに記載されていた情報です。
"Puget Custom Computers" の記事 "NVIDIA CUDA with Ubuntu 16.04 beta on a laptop (if you just cannot wait)" のURL:
https://www.pugetsystems.com/labs/hpc/NVIDIA-CUDA-with-Ubuntu-16-04-beta-on-a-laptop-if-you-just-cannot-wait-775/
警告: この用法を実行する事による危険性に関しては私は承知致しません。 私はこの方法を実行した事によって生じるいかなる損害も補償出来ません。 全てはあなた自身の責任の下に判断して下さい。
/usr/local/cuda/include/host_config.h
上記ファイルの中の該当箇所を下記のように先頭に " // " を付け足してコメント アウト致しました。
|
そして、Torch7のインストール用のシェル スクリプトを実行致します。
|
これで問題無くビルドに成功致しました。
上記のコマンドを実行したら、 " ~/.bashrc " と " ~/.profile " の最後に次の行が追加されました。
|
尚、 " xxxxxx " には各自のユーザー名が入ります。 " ~ " はホーム ディレクトリーを表します。
追加された行の最初にある " . " は " source " コマンドと同じ意味を持ち、引数に指定したファイルに書かれている文字列を実行するものだそうです。
ここで、次のコマンドを実行する事で、ログインし直さずに " torch-activate " が実行されます。
|
次回のログイン時からは上記のコマンドの実行は不要です。
" 端末 " から次のコマンドを実行して、 " 端末 " に " Torch " のロゴマークが表示されれば正常に使用出来る状態です。
|
必要があるか、また記述の仕方が正しいかどうかは存じませんが、 " ホーム ディレクトリー " にある " .profile " を編集して以下の行をファイルの最後に追記する事により、環境変数を設定致しました。
|
私は " CUDA 7.5 " をインストールしたので環境変数のパスに " cuda-7.5 " と書きましたが、各自の環境に合った名前に致します。
各々のパスは " : "(コロン) で区切られます。
" PATH= " で " PATH " という変数に値を代入します。
" LD_LIBRARY_PATH= " で " LD_LIBRARY_PATH " という変数に値を代入します。
" $PATH " 及び " $LD_LIBRARY_PATH " は既存のパスを表します。
" export " でパスを出力して環境変数を設定します。
" .profile " はUbuntuではユーザーのログイン時に読み込まれるファイルであると私は認識しております。
只、既に " torch-activate " が実行されているのですから、改めて " Torch " のパスを設定する必要は無いのかもしれません。
余談ですが、Linuxでは一般的にシェルに " bash " が使われているところ、Ubuntuではログイン シェルについては " bash " ですが、その他は " dash " が使われているそうです。
シェルやGUI、CUI、ファイル マネージャー、ログイン、端末、TTY、daemon等について、解り易く解説してくれているウェブ ページを勝手ながら紹介させて頂きます。
ブログ "主に言語とシステム開発に関して" の記事ページ "Linux上でシェルが実行される仕組みを,体系的に理解しよう (bash 中級者への道)" のURL:
http://language-and-engineering.hatenablog.jp/entry/20110617/p1
次に、必要な " LuaRocks " パッケージをインストール致しました。
|
説明ページに記載があった " Turbo " は、ウェブ アプリケーション関係のものですが、私はそれには関わらないので、これについてはインストール致しませんでした。
最後に、 " waifu2x " のgit リポジトリーをクローン致しました。
|
ここで、早速 " waifu2x " を試してみます。
" 端末 " で次のコマンドを実行致します。
|
しかし、画像処理プログラムである " GraphicsMagick " がインストールされていない場合はエラー メッセージが出ます。
~/waifu2x$ th waifu2x.lua
gm (GraphicsMagick) binary not found, please install (see www.graphicsmagick.org)
images/miku_small(noise_scale).png: 1.1321530342102 sec
この場合は下記の様にして " GraphicsMagick " をインストールします。
|
これで正常に動作する筈です。
これで準備が整いましたので、まずは添付されていた学習済みデータを用いて任意の画像の拡大を試してみました。
2倍の寸法にする拡大ですが、非常に素晴らしい画質でした。
以下のコマンドは作業ディレクトリーを " ~/waifu2x/ " としてあります。
" input_image " は拡大対象の画像ファイルのパスとファイル名を入力します。
" output_image " は保存する際の画像ファイルのパスとファイル名を入力します。
[レヴェル1のノイズ除去 + 2倍に拡大]
|
次に、自前の画像データ セットで人工ニューラル ネットワークに学習させる事を試みました。
私は学習用画像データ セットとして、自作のHTML5のCanvas要素とJavaScriptによってジェネレーティヴ アート画像を大量に自動生成させたものだけを使用致しました。
乱数による自動生成画像です。
自作のジェネレーティヴ アート画像自動生成プログラムは下記の " Yahoo!ボックス " にアップロードして公開しております。
御興味がございましたら、どうぞ御自由にお使い下さい。
使い方は簡単で、ダウンロードしたHTML ファイルをFirefoxなどHTML5対応のウェブ ブラウザーで開き、ブラウザーの設定で " .png " 形式の画像ファイルのダウンロード時にダイアログを表示させないようにした上で、 " Play / Stop " ボタンをクリックするだけです。
すると、自動生成された画像が10秒毎にPNG形式のファイルとしてブラウザーで設定されているダウンロード ディレクトリーに次々と2048枚までダウンロードされます。
ダウンロードし終わったら、セキュリティーを維持する為に必ずブラウザーのダウンロード設定を元に戻して下さい。
[Yahoo!ボックス]
http://yahoo.jp/box/4_Sq4x
https://c1.staticflickr.com/9/8199/28872340824_fe7e8fc4a7_o.png
自作のジェネレーティヴ アート画像自動生成プログラムが生成した大量のディジタル アートの1枚です。
https://c1.staticflickr.com/9/8171/29208180350_099d57a5fc_o.png
これらの画像を大量に学習させました。
尚この画像生成プログラムは、自作インタラクティヴ ディジタル アート プログラムから派生させたプログラムです。
基となったプログラムに関する私のブログ記事: HTML5のCamvasと "JavaScript" で音声処理と画像描画。
http://crater.blog.so-net.ne.jp/2016-06-30
因みに、初めwaifu2xを2048枚で学習させた後に、512枚を追加して " -resume " オプションで追加学習させるといった事も出来ました。
私は生成させた画像2048枚+512枚を " XnConvert " という一括画像処理が出来るフリー ソフトウェアで自動コントラスト調整し、waifu2xで学習させました。
尚、このプログラムで生成した画像データを用いて学習させたwaifu2xのモデルは充分に素晴らしい画質で拡大、ノイズ リダクションが出来ました。
"XnConvert" の公式ウェブサイトのURL:
http://www.xnview.com/en/xnconvert/
ところで、私が学習用画像データ セットをジェネレーティヴ アート画像だけにした理由は、例えば実写の写真に写り込んでいる色々の嫌なもの、汚いものをNNに見せて学習させた結果が適用されるのが嫌だからです。
もし、綺麗な女性のポートレート写真を拡大した際に、睫毛の拡大処理に厳つい男性の髭で学習されたパラメーターが使われていたら嫌だなあと、感覚的な問題ですが、私はそう思ったのです。
その為に以前、フラクタル画像やカオス図形を生成するアプリケーション ソフトウェア等を中心に幾つも試したのですが、フラクタル図形は2D、3D共に、大きな構造から始まって際限無く微細な構造が描かれて行く為細部がノイズになってしまう欠点があり、カオス図形という枠組みで見ても線描画や点描画が多く、最適なものは中々見つかりませんでした。
次に " Evolvotron " というアプリケーション ソフトウェアを試しました。
"Evolvotron" の公式ウェブサイトのURL:
http://www.bottlenose.net/share/evolvotron/
" Ubuntuソフトウェアセンター " からインストール致しました。
https://c1.staticflickr.com/1/674/23257755171_2a391b2cec_o.png
プログラムによって作られる幾つもの様式の図形、模様を組み合わせて画像を生成し、乱数のパラメーターによってそれが様々に変化します。
このソフトウェアはGUIで使用出来、メインのウィンドウには横6列、縦5行のランダムに生成された画像が小さく並んでおります。
ユーザーは、この中から好きなパターンを選んでクリックします。
すると、他の画像が、選んだ画像のパラメーターを元にして、変異(Mutate)した画像に置き換わります。
" Autocool " オプションにチェック マークを付けた状態で、これを繰り返して行くと、ユーザーの好みの画像へと収斂して行き、満足の行く作品が出来上がるのです。
途中で、 " Lock " して幾つかの画像を保持する事も出来、また、パラメーターのリセットや、パラメーターのファイルへの書き出しと読み込みも簡単に出来ます。
好みの画像は大きさを選んで別ウィンドウに大きく表示する事が出来ます。
コンテキスト メニューから保存が出来ます。
レンダリングのオプションとして、 " Oversampling (antialiasing) " で輪郭等を滑らかにしたり、 " Jitterd samples " でグラデーションにジッターを加えて、ざらつきを軽減したり出来ます。
実際にどの様な画像を生成したのかにつきましては、次の記事をご覧下さい。
ブログ記事: 進化型画像生成ソフトウェアの "Evolvotron" で作った画像。
http://crater.blog.so-net.ne.jp/2015-11-30
このEvolvotronというソフトウェアが生成した画像もそこそこ良かったのですが、私は更に、乱数だけに基づいた単一のアルゴリズムによる画像群だけで学習させたく思い、HTML5のCanvas要素とJavaScriptによってこれを実現する為に前述の自作プログラムを作成したのです。
そして大量の学習用画像データ セットが用意出来ました。
これにて漸く学習の準備が整いました。
" 端末 " からCUIで学習を行わせます。
以下のコマンドは作業ディレクトリーを " ~/waifu2x/ " としてあります。
" input_image " は拡大対象の画像ファイルのパスとファイル名を入力します。
" output_image " は保存する際の画像ファイルのパスとファイル名を入力します。
[学習済みデータ格納用ディレクトリーの作成]
|
[学習用画像リスト作成]
find '/home/xxxxx/xxxxx' -name "*.png" > data/image_list.txt
" xxxxx " の部分は各自の学習用画像ファイルがあるフォルダーのパスを入力します。
パスに半角スペースが含まれる場合等はパス全体をシングル クォーテーション記号で括ります。
[学習用データ変換]
|
続きまして、実際の学習処理を行いました。
[2倍拡大用の学習]
|
[2倍拡大 + 圧縮ノイズ低減処理用の学習]
|
ここで、 " Reference_1.png " は私が用意した画像ファイルです。
各自任意の画像ファイルを指定して下さい。
学習が進み、モデル データが更新される度に、 " /models/my_model/ " に指定した画像を拡大した結果が保存され、性能を確認出来ます。
" 2倍拡大 + ノイズ低減処理用の学習 " のコマンドの引数にある " -nr_rate 0.9 " はノイズ低減処理の強さです。
値が大きい程ノイズを消しますが、同時に細部の情報が失われてしまいます。
上記のコマンドを実行し、Ubuntuのシステム モニターでCPUとメモリーの使用率を見ていたところ、メイン メモリーは僅か12.1[GiB]程しか使用しておりませんでした。CPUはマルチスレッドで全稼働か、シングル スレッドで使用率100[%]となっておりました。
因みに初期のwaifu2xはより多くのメイン メモリーを使用しておりました。
改良によりメイン メモリーの使用率を低減出来たようです。
上記のコマンドを実行すると、画像ファイル数の1/20の数の評価用データ セットが作られるようです。
引数で指定せず、初期設定では内部4世代 x 50世代の合計200回の反復処理が行われます。
1世代毎に学習と評価が行われ、評価が過去最高であればモデル データが更新されます。
画面には " loss " , " MSE ", " PSNR " が表示されます。
" MSE " とは " Mean Squared Error " の事で、 " 平均平方誤差 " と言います。
簡略化して述べると、基準用の高解像度画像と、処理した結果の画像との間の差分を取り、これを2乗して平均値を出した値の事だそうです。
処理が上手く行って基準用画像に近付く程、MSEの値は小さくなり、0に近付きます。
PSNR (Peak Signal-to-Noise Ratio / ピーク信号対雑音比)はMSEの値から計算されるそうです。
尚、誤差をRMS(Root Mean Square / 二乗平均平方根)としてRMS Errorとする場合も多いようです。
このMSEやPSNRの値は、学習が進む毎に徐々に変化し難くなって行きます。
また、値を更新させる割合である " learning rate decay " も指数関数的に小さくなっていきます。
私は以前、自作天体望遠鏡とコンパクト ディジタル カメラで撮影した月の画像を合成処理した際は処理完了までに約1週間掛かりましたが、今回の機械学習は僅か1日間で済みました。
上記の処理で学習(トレーニング)は完了です。
次は学習済みモデル データを使用した画像処理です。
以下のコマンドは作業ディレクトリーを " ~/waifu2x/ " としてあります。
" input_image " は拡大対象の画像ファイルのパスとファイル名を入力します。
" output_image " は保存する際の画像ファイルのパスとファイル名を入力します。
[学習させたモデル データによる2倍拡大]
|
[学習させたモデル データによる2倍拡大 + 圧縮ノイズ低減処理]
|
学習が終わった畳み込み人工ニューラル ネットワークによる画像の拡大結果は非常に素晴らしいものでした。
どんな種類の画像でも元からその解像度だったのではないかと思える程綺麗に拡大出来ております。
コンピューター生成画像だけを使った学習実験は大成功でした。
以下に使用前後の比較画像を載せますが、ブログ内では縮小表示されているので、画像下のURLからオリジナルのファイルをご覧下さい。
https://c1.staticflickr.com/9/8340/28871566744_76f7899b1d_o.png
左から順に、自前のジェネレーティヴ アート画像群による学習済みモデル データによって " waifu2x " で2回2倍に拡大(4倍)した画像と、ランタナの花の元の写真と、 " Lanczos " で同様に拡大した画像との比較画像です。
https://c1.staticflickr.com/9/8323/29416402671_97b056ff80_o.png
こちらは記事の最初に掲載した比較用の画像です。
Lanczos補間法によるものと比べて輪郭は鋭利であり、また、アンダーシュートとオーヴァーシュートが無くて綺麗です。
" waifu2x " の作者様、及び、関係するプログラム等の作者様方には心より感謝申し上げます。
本当にありがとうございます。
ところで、拡大の他にもし、不鮮明なぼやけた画像を鮮明にしたい場合には他の何らかのソフトウェアを用いて " Iterative Deconvolution " という処理をするのが効果的です。
オープン ソース ソフトウェアの " GIMP " という画像編集ソフトウェアに " G'MIC - GREYC's Magic for Image Computing " というプラグインがございまして、これの機能の1つに " Iterative Deconvolution " がございます。
" GIMP 2.9.5 "内のメニュー項目は " Filters " - " G'MIC... " - " Details " - " Sharpen [richardson-lucy] " となっております。
これを使用するのが最も簡単であるかと存じます。
"GIMP" の公式ウェブサイトのURL:
http://www.gimp.org/
"G'MIC" のウェブサイトのGIMP プラグインのページのURL:
http://gmic.eu/gimp.shtml
更に、点拡がり関数の画像を自前で用意して様々なメソッドを使えるという点で、Java VM上で動作するオープン ソース ソフトウェアの " ImageJ " にプラグインを導入したものも便利だと思います。
" ImageJ " は医療や生物学等の研究者が使用する事が多いようです。
"ImageJ" の公式ウェブサイトのURL:
http://imagej.nih.gov/ij/
Gaussian_PSF_3D.class:
ガウス関数型点拡がり関数の画像スタックを作るプラグインです。
http://www.optinav.com/Convolve_3D.htm
Iterative_Deconvolution.class:
反復型の、コンヴォリューションとデコンヴォリューションの為のプラグインです。
http://www.optinav.com/Iterative-Deconvolution.htm
Iterative_Deconvolve_3D.class:
2Dと3Dの非負の反復型のデコンヴォリューションの為のプラグインです。
http://www.optinav.com/Iterative-Deconvolve-3D.htm
"Audacious" プレイリストの楽曲ファイルのディレクトリー名を変更しました。 [ソフトウェア]
私はUbuntu PCに音楽CDから非圧縮のWAVE ファイルで取り込んだファイルを保存してあります。
また、音楽再生ソフトウェアの " Audacious " でそれらの楽曲のプレイリストを作成してあります。
そしてオーディオ システムへ出力して音楽を再生して聴いております。

ですが、私は最も昔はCRT ディスプレイ一体型のMacintoshで音楽CDを再生し、次にノート型PCのPowerBook G4で純粋な音楽再生ソフトウェアだったiTunesで音楽CDから非圧縮のAIFF ファイルで取り込んでヘッドフォンやオーディオ システムで再生するようになり、その後はWindows Vista、Window 7のデスクトップ PCで自分でデザインや機能をカスタマイズした " foobar2000 " でWAVE ファイルと " CUE シート " で管理しておりました。
その音楽ファイルが入ったフォルダーをそのままUbuntu PCに移転した上で、AudaciousにCUE シートを読み込ませてプレイリストを作り直した状態で使用しておりましたので、昨日までフォルダー名が " foobar2000 " のままとなっておりました。
プレイリストの作り直しをせずに、これを固有名詞を含まない、 " Music " というフォルダー名に変更しようと思いました。
当該フォルダーの名前の変更と、プレイリストのデータ ファイルの書き換えを致しました。
Audaciousでは、次のディレクトリーにプレイリストのデータ ファイルがあります。
~/.config/audacious/playlists/
" ~/ " はホーム ディレクトリーです。
この中にある " xxxx.audpl " ファイルを1つずつgeditで開いて " 置換 " 機能でファイルの中に記述されていた " /foobar2000/ " を " /Music/ " に一括変更致しました。
そしてAudaciousを起動すると、 " 曲の情報 " として変更後の正しいファイル パスが表示され、正常に楽曲再生が出来ました。
また、音楽再生ソフトウェアの " Audacious " でそれらの楽曲のプレイリストを作成してあります。
そしてオーディオ システムへ出力して音楽を再生して聴いております。
ですが、私は最も昔はCRT ディスプレイ一体型のMacintoshで音楽CDを再生し、次にノート型PCのPowerBook G4で純粋な音楽再生ソフトウェアだったiTunesで音楽CDから非圧縮のAIFF ファイルで取り込んでヘッドフォンやオーディオ システムで再生するようになり、その後はWindows Vista、Window 7のデスクトップ PCで自分でデザインや機能をカスタマイズした " foobar2000 " でWAVE ファイルと " CUE シート " で管理しておりました。
その音楽ファイルが入ったフォルダーをそのままUbuntu PCに移転した上で、AudaciousにCUE シートを読み込ませてプレイリストを作り直した状態で使用しておりましたので、昨日までフォルダー名が " foobar2000 " のままとなっておりました。
プレイリストの作り直しをせずに、これを固有名詞を含まない、 " Music " というフォルダー名に変更しようと思いました。
当該フォルダーの名前の変更と、プレイリストのデータ ファイルの書き換えを致しました。
Audaciousでは、次のディレクトリーにプレイリストのデータ ファイルがあります。
~/.config/audacious/playlists/
" ~/ " はホーム ディレクトリーです。
この中にある " xxxx.audpl " ファイルを1つずつgeditで開いて " 置換 " 機能でファイルの中に記述されていた " /foobar2000/ " を " /Music/ " に一括変更致しました。
そしてAudaciousを起動すると、 " 曲の情報 " として変更後の正しいファイル パスが表示され、正常に楽曲再生が出来ました。

御協力をお願い申し上げます。
分散型インターネット検索エンジンである "YaCy" の公式ウェブ サイトのURL:
http://yacy.net/en/index.html
一緒に公正公平なインターネット検索を実現しましょう!
私のブログ記事: YaCy
2017年9月1日時点に於ける
最新ヴァージョン: 1.921/9342
Java8以上が必要です。
ウェブ アプリケーション プログラム
自作のHTML5 ウェブ アプリケーション プログラムがございます。
Canvas要素とWeb Audio APIとJavaScriptで製作致しました。

ウェブアプリ専用ブログの記事: ウェブ音楽プレイヤー
音楽ファイルの再生、キーボード演奏などが出来ます。
ヴィジュアライザーを実装してあります。
プレイリスト自動保存可能です。
重低音プレイが出来ます。
こちらは迷路自動生成プログラムです。

ウェブアプリ専用ブログの記事: 迷路自動生成プログラム
迷路の規模を変えられます。

本ブログの記事: HTML5のCamvasと "JavaScript" で音声処理と画像描画。
音の生成と模様や図形の描画と幾つかの物理シミュレーションを実装してあります。
Canvas要素とWeb Audio APIとJavaScriptで製作致しました。
ウェブアプリ専用ブログの記事: ウェブ音楽プレイヤー
音楽ファイルの再生、キーボード演奏などが出来ます。
ヴィジュアライザーを実装してあります。
プレイリスト自動保存可能です。
重低音プレイが出来ます。
こちらは迷路自動生成プログラムです。
ウェブアプリ専用ブログの記事: 迷路自動生成プログラム
迷路の規模を変えられます。
本ブログの記事: HTML5のCamvasと "JavaScript" で音声処理と画像描画。
音の生成と模様や図形の描画と幾つかの物理シミュレーションを実装してあります。


